MongoDB Cluster
- MongoDB
- Replica Set
- Sharded clusters
- Triển khai trên Cloud như thế nào?
- Vector Search and RAG
- Một số vấn đề khác
MongoDB
MongoDB là một cơ sở dữ liệu mã nguồn mở và là cơ sở dữ liệu NoSQL
Vậy NoSQL là gì?
- NoSQL là 1 dạng CSDL mã nguồn mở và được viết tắt bởi None-relational SQL.
- NoSQL được phát triển trên js framework với kiểu dữ liệu là JSON và dạng dữ liệu theo kiểu key và value
- NoSQL ra đời như là một mảnh vá cho những khuyết điểm và thiếu sót cũng như hạn chế của mô hình dữ liệu quan hệ RDBMS về tốc độ, tính năng, khả năng mở rộng
- NoSQL có thể dễ dàng mở rộng dữ liệu mà không lo tới những vấn đề như tạo khóa ngoại, khóa chính, kiểm tra ràng buộc .v.v…
- NoSQL bỏ qua tính toàn vẹn của dữ liệu và transaction để đối lấy hiệu suất nhanh và khả năng mở rộng.
Vì MongoDB là cơ sở dữ liệu NoSQL nên nó cũng là một cơ sở dữ liệu hướng tài liệu (document), các dữ liệu được lưu trữ trong document theo kiểu JSON thay vì dạng bảng như CSDL quan hệ nên tốc độ truy vấn sẽ nhanh.
Một số đặc tính nổi bật của MongoDB:
- Cấu trúc dữ liệu linh hoạt, không ràng buộc cứng các field dữ liệu từ đầu
- Dễ dàng mở rộng theo chiều ngang
- Hỗ trợ query nhanh vì đã lược bỏ bớt các mối quan hệ ràng buộc cũng như cơ chế caching
- Hỗ trợ bộ index xử lí đa dạng cho các nhau cầu khác nhau.
Tiếp theo ta sẽ tìm hiểu cách triển khai MongoDB bằng Docker.
Image chính thức của MongoDB trên Docker Hub là mongo
Tải bản mới nhất:
docker pull mongo:latest
Chạy MongoDB container
sudo docker run -d --name mongodb -p 27017:27017 mongo:latest
Kiểm tra xem container có đang chạy không bằng:
sudo docker ps
❯ sudo docker ps
CONTAINER ID IMAGE COMMAND CREATED STATUS PORTS NAMES
cde338c2600a mongo:latest "docker-entrypoint.s…" 21 seconds ago Up 20 seconds 0.0.0.0:27017->27017/tcp, [::]:27017->27017/tcp mongodb
Xem chi tiết hơn tại đây
Phần này mình chỉ demo một số tính năng của Docker nên sẽ pull latest image, nhưng trên thực tế thì nên chọn một phiên bản cố định để thống nhất môi trường phát triển và hơn nữa là có document đầy đủ để tiện theo dõi hơn.
Vào mongosh bên trong mongodb container:
sudo docker exec -it mongodb mongosh
Kiểm tra thử bằng lệnh:
test> db.version()
8.2.5
test>
Một số thuật ngữ trong MongoDB:
-
Document: Một bản ghi thuộc một collection được gọi là một document. Các document lần lượt bao gồm các trường tên và giá trị.
-
_id: là trường bắt buộc có trong mỗi document. Trường _id đại diện cho một giá trị duy nhất trong document MongoDB. Trường _id có thể được hiểu như là khóa chính trong document, còn document có thể được xem như là một hàng trong bảng của CSDL quan hệ.
-
Collection: là nhóm của nhiều document trong MongoDB. Collection có thể được hiểu là một bảng tương ứng trong cơ sở dữ liệu quan hệ. Collection nằm trong một cơ sở dữ liệu duy nhất. Các collection không phải định nghĩa các cột, các hàng hay kiểu dữ liệu trước.
-
Cursor: là một con trỏ đến tập kết quả của một truy vấn. Client có thể lặp qua cursor để lấy dần các document trong tập kết quả.
Ví dụ khi ta chạy:
db.users.find()
thì kết quả trả về sẽ là một con trỏ đến tập kết quả của truy vấn này. Ta có thể lặp qua con trỏ này để lấy từng document trong tập kết quả. Vì sao lại cần có cursor? Giả sử trong trường hợp collection có tới 10 triệu document thì việc MongoDB trả 1 lần toàn bộ 10 triệu records sẽ khiến RAM quá tả.
-
Database: nơi chứa các collection, giống với CSDL RDMS chúng chứa các bảng. Mỗi DB có một tập tin riêng lưu trữ trên bộ nhớ vật lí. Một máy chủ MongoDB có thể chứa nhiều DB.
- Field: là một cặp name-value trong một document. Một document có thể có không hoặc nhiều trường. Các trường giống các cột ở cơ sở dữ liệu quan hệ.
-
JSON: Là viết tắt của JS Object Notation.
- Index: là một CTDL đặ cbiệt giúp tăng tốc độ truy vấn bằng cách cho phép MongoDB tìm dữ liệu nhanh hơn thay vì phải quét toàn bộ collection.
Một số thứ về JSON:
JSON
JSON là viết tắt cho Javascript Object Notation là một loại dữ liệu dựa trên chuẩn syntax của Javascript Object. Ví dụ:
{"username" : "duccorp",
"school": "uit",
"github": "ken3k06"
...}
JSON có thể được lưu vào file, có phần mở rộng là .json ,hoặc có thể dùng lưu lưu vào một record trong CSDL, v.v… Nó có định dạng đơn giản, bao gồm 2 phần chính đó là key và value, ngoài ra nó cũng dễ dàng sử dụng và truy vấn hơn XML rất nhiều. Thực tế, dữ liệu JSON hợp lệ có thể ở hai định dạng khác nhau:
- Đầu tiên là dạng tập hợp các cặp key-value được bao bởi một cặp dấu ngoặc nhọn
{...}. Như ví dụ ở trên - Dạng thứ hai là tập hợp danh sách có thứ tự các cặp key-value được phân tách bởi dấu phẩy và được bao bởi một cặp dấu ngoặc vuông
[...]Ví dụ:[ { "username" : "duccorp", "school" : "uit", "github" : "ken3k06" }, { "username" : "dangminhtu", "school" : "uit", "github" : "little" }, { "username" : "nguyentrongnhan", "school" : "uit", "github" : "nhantablop" } ]
Ta nên sử dụng JSON trong tình huống nào? Trong trường hợp ta muốn lưu trữ dữ liệu đơn thuần, tức là dưới dạng metadata ở phía server. Chuỗi JSON sẽ được lưu vào database và sau đó khi cần thì dữ liệu sẽ được giải mã. Và ngoài ra cũng còn nhiều ứng dụng khác nhưng mình xin dành cho các bài sau để nói sâu hơn về chủ đề này. Xem thêm tại đây: https://datatracker.ietf.org/doc/html/rfc8259
Trong Python có sẵn module json để ta làm việc với kiểu dữ liệu này
Để chuyển các dữ liệu trong Python sang kiểu dữ liệu JSON thì ta dùng json.dumps hoặc json.dump
>>> import json
>>> data = {"username" : "duccorp", "option" : "get_flag"}
>>> json.dumps(data)
'{"username": "duccorp", "option": "get_flag"}'
>>>
Về sự khác nhau giữa hai methods này thì mọi người đọc doc của python để biết thêm chi tiết: Doc
Tương tự ta cũng sẽ có json.load() và json.loads()
>>> d = json.dumps(data).encode()
>>> e = json.loads(d.decode())
>>> type(e)
<class 'dict'>
>>> e
{'username': 'duccorp', 'option': 'get_flag'}
>>> d = json.dumps(data)
>>> type(d)
<class 'str'>
>>>
Làm quen với MongoDB
Doc của MongoDB: https://www.mongodb.com/docs/manual/
Đầu tiên trong mongosh, để kiểm tra các db hiện có:
test> show dbs
admin 40.00 KiB
config 60.00 KiB
local 40.00 KiB
Để tạo một db mới, xài lệnh use + db_name.
local> use shop
switched to db shop
shop> show dbs
admin 40.00 KiB
config 60.00 KiB
local 40.00 KiB
shop>
db shop vẫn chưa được tạo do bên trong nó vẫn chưa có dữ liệu. Nhưng trước đó thì mình cần tạo một volume để lưu trữ dữ liệu của container này cho các lần làm việc sau.
sudo docker stop mongodb && sudo docker rm mongodb
sudo docker volume create mongo-data
Chạy lại container với volume mới tạo:
sudo docker run -d --name mongodb -p 27017:27017 -v mongo-data:/data/db mongo:latest
Tạo collection và thêm document vào collection:
shop> db.createCollection('users');
{ ok: 1 }
shop> db.users.insert({name:'Duc', gender:'male'});
DeprecationWarning: Collection.insert() is deprecated. Use insertOne, insertMany, or bulkWrite.
{
acknowledged: true,
insertedIds: { '0': ObjectId('69aa391023aa66e9208563b1') }
}
shop> db.users.insertOne({name:'Tu', gender:'male'});
{
acknowledged: true,
insertedId: ObjectId('69aa392223aa66e9208563b2')
}
shop>
insert sẽ có 3 lệnh chính là insertOne, insertMany và bulkWrite.
Xem các collection trong db hiện tại:
show collections
Xem toàn bộ dữ liệu trong collection users:
shop> db.users.find()
[
{
_id: ObjectId('69aa391023aa66e9208563b1'),
name: 'Duc',
gender: 'male'
},
{
_id: ObjectId('69aa392223aa66e9208563b2'),
name: 'Tu',
gender: 'male'
},
{
_id: ObjectId('69aa3a0e23aa66e9208563b3'),
name: 'Nhan',
gender: 'male'
},
{
_id: ObjectId('69aa3a0e23aa66e9208563b4'),
name: 'Dung',
gender: 'male'
}
]
shop>
Hoặc format đẹp hơn:
db.users.find().pretty()
Tìm document theo điều kiện:
db.users.find({name:'Duc'})
Cập nhật 1 document hoặc thêm field vào bằng lệnh updateOne,updateMany.
}
shop> db.users.updateOne({name:'Duc'}, {$set: {age: 24}})
{
acknowledged: true,
insertedId: null,
matchedCount: 1,
modifiedCount: 1,
upsertedCount: 0
}
shop> db.users.find({name:'Duc'})
[
{
_id: ObjectId('69aa391023aa66e9208563b1'),
name: 'Duc',
gender: 'male',
age: 24
}
]
shop>
lúc đầu không có field age trong document của Duc, sau khi chạy lệnh update thì field này đã được thêm vào và có giá trị là 24.
Trong trường hợp có nhiều users cùng tên thì ta có thể dùng updateMany để cập nhật tất cả các document này cùng lúc hoặc update theo ObjectId.
Kiểm tra lại volume để xem dữ liệu đã được cập nhật chưa:
Có thể dùng lệnh sau để kiểm tra vị trí lưu volume:
sudo docker inspect mongodb
"Mounts": [
{
"Type": "volume",
"Name": "mongo-data",
"Source": "/var/lib/docker/volumes/mongo-data/_data",
"Destination": "/data/db",
"Driver": "local",
"Mode": "z",
"RW": true,
"Propagation": ""
},
Xem dữ liệu:
sudo ls /var/lib/docker/volumes/mongo-data/_data
collection-216d347a-98fc-4a2b-ac5e-d58832aa3a80.wt index-47403e43-b296-4411-b087-551d4b072589.wt journal _tmp WiredTiger.wt
collection-82d45b8c-6e12-49b4-b42e-ebe504e559da.wt index-5053806c-baed-410c-addc-de47f2ab9d36.wt _mdb_catalog.wt WiredTiger
collection-d60b55d8-28d3-420b-a1d6-fb96d6a1a988.wt index-63775c2b-0fb9-42b5-b35e-05f6c3430e77.wt mongod.lock WiredTigerHS.wt
collection-f1854e35-c8f7-4e03-b8d5-d4918a1b1f59.wt index-a2824842-8f7c-493e-801d-0c6f8877a562.wt sizeStorer.wt WiredTiger.lock
diagnostic.data index-d579bc7f-67ee-40c2-b66b-274baafff5e0.wt storage.bson WiredTiger.turtle
Vậy là đã có dữ liệu được lưu vào rồi.
Thử tắt và bật lại container để kiểm tra dữ liệu có được lưu lại hay không:
sudo docker stop mongodb && sudo docker start mongodb
Tiếp theo mình sẽ thử connect tới MongoDB thông qua python.
Ở đây mình sẽ sử dụng thư viện pymongo để làm việc này.
Doc của MongoDB: pymongo
from pymongo import MongoClient
uri = "mongodb://127.0.0.1:27017/"
client = MongoClient(uri)
try:
print(client.list_database_names())
except Exception as e:
print(e)
Replica Set
Một replica set trong MongoDB là một nhóm các tiến trình của MongoDB duy trì cùng một bộ dữ liệu. Các replica set cung cấp tính dự phòng và sẵn sàng cao và là cơ sở để triển khai các cluster MongoDB.
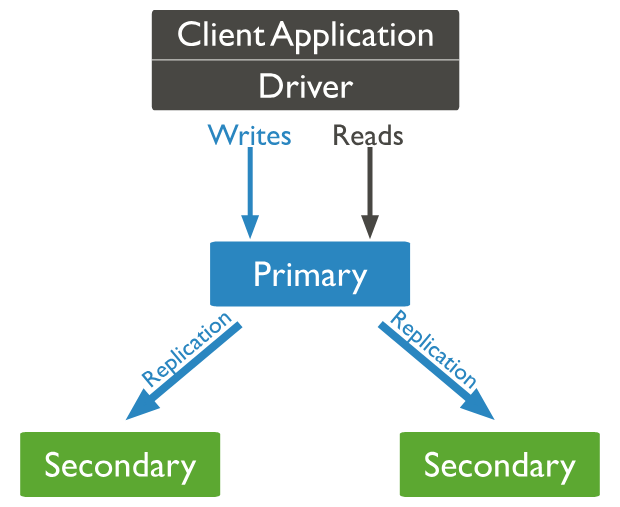
Một replica set tiêu chuẩn thường có ít nhất 3 node như sau:
- Một primary node: node này sẽ nhận tất cả các hoạt động ghi và đọc mặc định. Mỗi replica set chỉ có một primary node duy nhất tại một thời điểm.
- Một secondary node : thực hiện sao phép dữ liệu từ primary node thông qua các thao tác từ oplog. Primary node sẽ ghi lại tất cả các thay đổi vào một bản nhật kí gọi là oplog.
- Một arbiter node: node này không lưu trữ dữ liệu và không tham gia vào quá trình sao chép dữ liệu. Arbiter node chỉ có nhiệm vụ tham gia vào quá trình bầu cử khi primary node gặp sự cố để đảm bảo rằng replica set luôn có một primary node hoạt động.
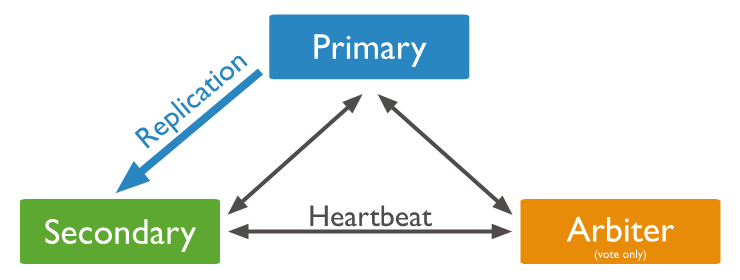
Mỗi node trong replica set sẽ chỉ thuộc về đúng replica set đó và không thể tham gia vào replica set khác.
Khi node primary gặp sự cố, các node secondary sẽ nhận thấy thông qua cơ chế heartbeat và sẽ tiến hành bầu cử để chọn ra một node secondary mới trở thành primary. Quá trình này đảm bảo rằng hệ thống vẫn có thể tiếp tục hoạt động mà không bị gián đoạn.
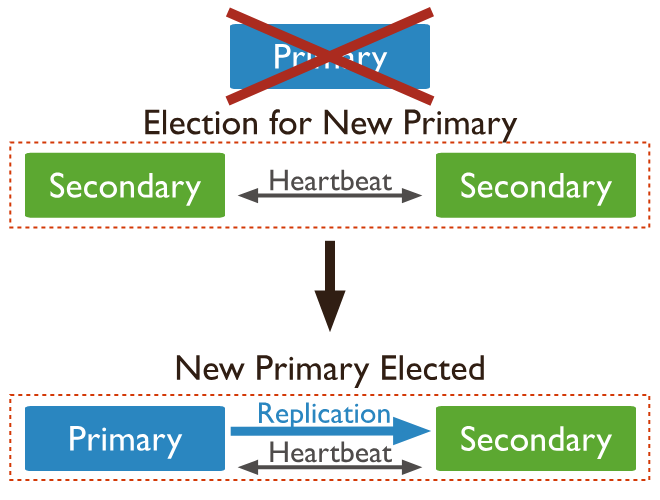
Node gặp sự cố sau khi được phục hồi trở lại sẽ trở thành một secondary node tham gia vào replica set này.
Bây giờ ta sẽ thử triển khai một replica set đơn giản với 3 node bằng docker compose. Tham khảo thêm tại đây
Lưu ý thêm, chúng ta cần 2 yếu tố để các service MongoDB có thể join vào cùng Replica Set:
- Cùng chia sẻ 1 key chung để xác thực.
- Cùng chung một mạng, có thể nhìn thấy nhau và ping đến nhau.
Cấu trúc file docker-compose.yml như sau:
version: "3.8"
services:
mongo1:
image: mongo:latest
container_name: mongo1
command: ["mongod", "--replSet", "rs0", "--bind_ip_all", "--port", "27017"]
ports:
- "27017:27017"
volumes:
- mongo1_data:/data/db
networks:
- mongo-cluster
mongo2:
image: mongo:latest
container_name: mongo2
command: ["mongod", "--replSet", "rs0", "--bind_ip_all", "--port", "27017"]
ports:
- "27018:27017"
volumes:
- mongo2_data:/data/db
networks:
- mongo-cluster
mongo3:
image: mongo:latest
container_name: mongo3
command: ["mongod", "--replSet", "rs0", "--bind_ip_all", "--port", "27017"]
ports:
- "27019:27017"
volumes:
- mongo3_data:/data/db
networks:
- mongo-cluster
volumes:
mongo1_data:
mongo2_data:
mongo3_data:
networks:
mongo-cluster:
driver: bridge
Sau khi chạy docker-compose up -d thì ta đã có 3 node MongoDB chạy ngầm trên máy. Tiếp theo ta sẽ vào mongosh của node mongo1 để cấu hình replica set. Tạo một file init-rs.js với nội dung như sau:
rs.initiate({
_id: "rs0",
members: [
{ _id: 0, host: "mongo1:27017" },
{ _id: 1, host: "mongo2:27017" },
{ _id: 2, host: "mongo3:27017" }
]
})
rs.status()
Sau đó chạy lệnh sau để vào mongosh của node mongo1 và chạy file init-rs.js này:
docker exec -i mongo1 mongosh < init-rs.js
Tiếp theo ta vào mongosh bất kì để kiểm tra
rs.status()
thì sẽ thấy có một node được đặt làm primary còn hai node còn lại là secondary.
Test đồng bộ:
Ở secondary node:

Một khái niệm nữa mà mình muốn đề cập tới đó là keyfile access control. Keyfile là một phương pháp được sử dụng cho cơ chế internal authentication giữa các node trong replica set. Keyfile đóng vai trò như một mật khẩu chung được chia sẻ giữa các node trong replica set để xác thực lẫn nhau. Khi một node cố gắng kết nối với node khác trong replica set, nó sẽ sử dụng keyfile để chứng minh rằng nó là một phần của replica set và có quyền truy cập vào dữ liệu.
Một số quy định về tạo key xem tại đây
Demo:
Đầu tiên mình sẽ tạo một keyfile mới:
openssl rand -base64 756 > key/mongo-keyfile
chmod 400 key/mongo-keyfile
sudo chown 999:999 key/mongo-keyfile
Lần đầu tiên chạy, mình không thêm dòng sudo chown 999:999 key/mongo-keyfile vào. Kết quả là services không chạy được.
Để kiểm tra xem chuyện gì đang xảy ra thì mình cần đọc logs của container bằng lệnh:
sudo docker logs mongo1
{"t":{"$date":"2026-03-06T07:44:42.984+00:00"},"s":"F", "c":"CONTROL", "id":20575, "ctx":"main","msg":"Error creating service context","attr":{"error":"Location5579201: Unable to acquire security key[s]"}}
Lỗi này theo mình nghĩ, có lẽ nằm ở việc container không có quyền đọc file key này. Sau đó mình thêm dòng sudo chown 999:999 key/mongo-keyfile để đổi quyền sở hữu của file này sang user có id là 999. Để biết được mongodb có user id là 999 thì mọi người kiểm tra bằng lệnh sau:
❯ sudo docker run --rm mongo:latest id mongodb
uid=999(mongodb) gid=999(mongodb) groups=999(mongodb)
Còn đối với file key, ta chỉ được set quyền 400 cho file này, nếu không thì MongoDB sẽ báo lỗi.
Tiếp theo cần cập nhật lại file YAML, sửa hoàn chỉnh lại như sau:
version: "3.8"
services:
mongo1:
image: mongo:latest
container_name: mongo1
command: ["mongod", "--replSet", "rs0", "--bind_ip_all", "--keyFile", "/key/mongo-keyfile"]
ports:
- "27017:27017"
volumes:
- mongo1_data:/data/db
- ./key/mongo-keyfile:/key/mongo-keyfile:ro
networks:
- mongo-cluster
healthcheck:
test: ["CMD", "mongosh", "--eval", "db.adminCommand('ping')"]
interval: 5s
timeout: 5s
retries: 5
mongo2:
image: mongo:latest
container_name: mongo2
command: ["mongod", "--replSet", "rs0", "--bind_ip_all", "--keyFile", "/key/mongo-keyfile"]
ports:
- "27018:27017"
volumes:
- mongo2_data:/data/db
- ./key/mongo-keyfile:/key/mongo-keyfile:ro
networks:
- mongo-cluster
healthcheck:
test: ["CMD", "mongosh", "--eval", "db.adminCommand('ping')"]
interval: 5s
timeout: 5s
retries: 5
mongo3:
image: mongo:latest
container_name: mongo3
command: ["mongod", "--replSet", "rs0", "--bind_ip_all", "--keyFile", "/key/mongo-keyfile"]
ports:
- "27019:27017"
volumes:
- mongo3_data:/data/db
- ./key/mongo-keyfile:/key/mongo-keyfile:ro
networks:
- mongo-cluster
healthcheck:
test: ["CMD", "mongosh", "--eval", "db.adminCommand('ping')"]
interval: 5s
timeout: 5s
retries: 5
mongo-init:
image: mongo:latest
container_name: mongo-init
depends_on:
mongo1:
condition: service_healthy
mongo2:
condition: service_healthy
mongo3:
condition: service_healthy
volumes:
- ./init-rs.js:/init-rs.js:ro
networks:
- mongo-cluster
entrypoint: ["mongosh", "--host", "mongo1", "--file", "/init-rs.js"]
volumes:
mongo1_data:
mongo2_data:
mongo3_data:
networks:
mongo-cluster:
driver: bridge
Một vài ghi chú trước khi qua các phần tiếp theo:
Thay vì để mặc định mongo:latest thì mình nên chọn một phiên bản cố định để tránh vấn đề tương thích.
Ở đây mình sẽ chỉnh lại thành mongo:7.0.
Hơn nữa ở trên mình có tạo thêm một service mới là mongo-init để tự động thiết lập replica set sau khi các node đã sẵn sàng.
Tuy nhiên thì nó chạy không thành công vì thiếu xác thực giữa các node.
❯ docker logs mongo-init
Waiting for nodes to be ready... sleep 10
MongoServerError: Command replSetInitiate requires authentication
Cách xử lí đơn giản nhất là bỏ luôn phần mongo-init và vào trực tiếp trong mongo1 để chạy các lệnh thiết lập replica set và set user admin.
Sau đó mình đọc doc và phát hiện được rằng đây là một cơ chế của mongodb gọi là localhost exception.
Với mỗi mongod instance thì cơ chế này áp dụng khi chưa có bất cứ users hay role nào được thiết lập trong instance đó. Nó cho phép ta truy cập vào hệ thống để thiết lập replica set và user mà không yêu cầu quyền xác thực nào. Init container ở trên nằm trong một mạng chung là mongo-cluster, dù vậy thì nó vẫn không phải là localhost của container mongo1 nên không thể áp dụng được cơ chế này.
Hiện tại thì mình chưa biết cách xử lí phần này nên sẽ tạm skip.
Update: Sau một hồi suy ngẫm thì mình nghĩ có thể giải quyết vấn đề trên như sau:
mongo-init:
image: mongo:7.0
env_file:
- .env
container_name: mongo-init
networks:
- mongo-cluster
depends_on:
mongo1: { condition: service_healthy }
mongo2: { condition: service_healthy }
mongo3: { condition: service_healthy }
mongo4: { condition: service_healthy }
entrypoint:
- bash
- -c
- |
echo "Starting initialization workflow..."
until mongosh --host mongo1:27017 -u "$$MONGO_INITDB_ROOT_USERNAME" -p "$$MONGO_INITDB_ROOT_PASSWORD" --authenticationDatabase admin --eval "db.adminCommand('ping')" --quiet; do
echo "Waiting for auth to be ready on mongo1..."
sleep 3
done
mongosh --host mongo1:27017 -u "$$MONGO_INITDB_ROOT_USERNAME" -p "$$MONGO_INITDB_ROOT_PASSWORD" --authenticationDatabase admin <<EOF
let status;
try { status = rs.status(); } catch (e) { status = { ok: 0 }; }
if (status.ok === 0) {
rs.initiate({
_id: "rs0",
members: [
{ _id: 0, host: "mongo1:27017", priority: 3 },
{ _id: 1, host: "mongo2:27017", priority: 2 },
{ _id: 2, host: "mongo3:27017", priority: 1 },
{ _id: 3, host: "mongo4:27017", priority: 0 }
]
});
}
EOF
Ở đây mình sẽ lưu mật khẩu vào trong file .env và sử dụng biến môi trường để truy cập vào bên trong entrypoint của container mongo-init. Bằng cách này thì mình có thể bỏ qua cơ chế localhost exception và thiết lập mật khẩu ngay từ đầu cho user admin sau đó từ mongo-init truy cập thẳng vào mongo1 để thiết lập replica set.
Testing một số trường hợp:
Trường hợp 1: Shutdown 1 node primary và kiểm tra xem các node còn lại có nhận ra sự cố và tiến hành bầu cử để chọn ra một primary mới hay không.
Shutdown container mongo1:
docker stop mongo1
Sau đó kiểm tra mongo2:
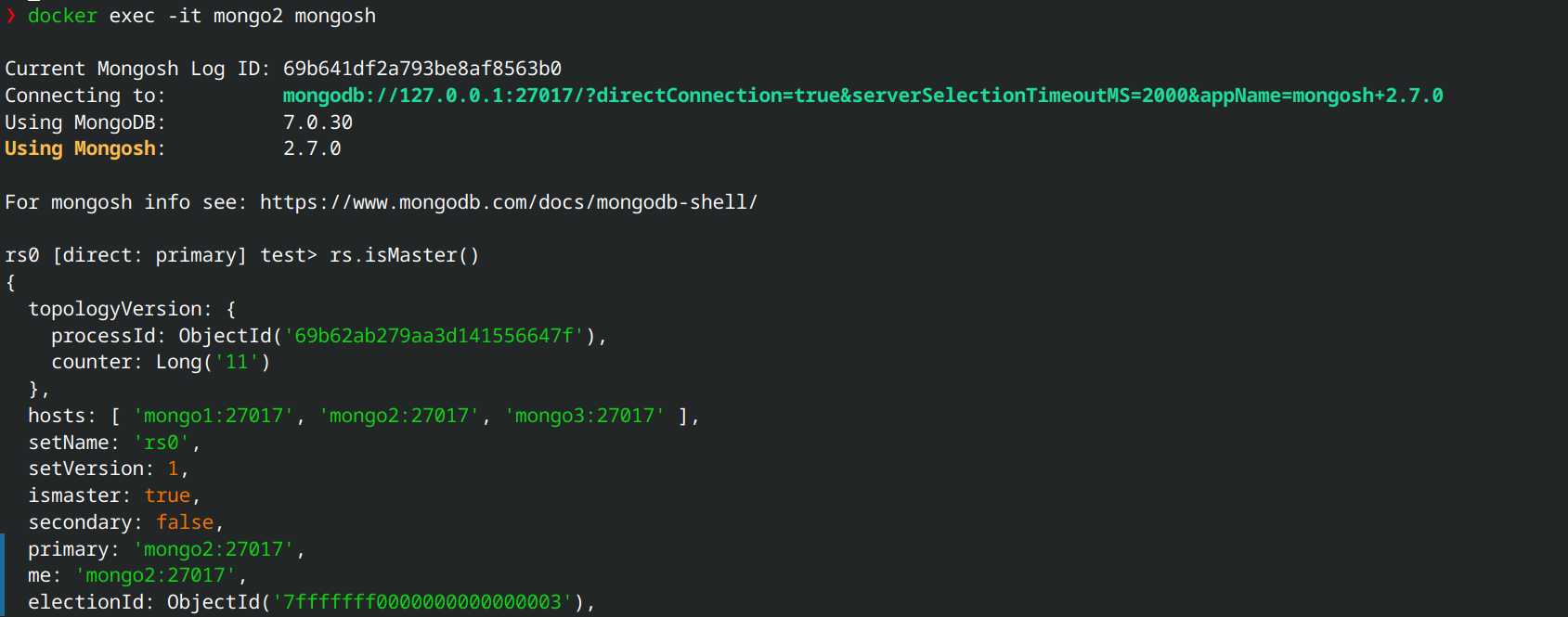
Priority càng cao thì node đó sẽ được chọn làm primary trước.
Trường hợp 2: Thêm vào một node mới
Start lại container mongo1 và thêm vào một node mới trong set, ta tạm gọi là mongo4
mongo4:
image: mongo:7.0
env_file:
- .env
container_name: mongo4
command: ["mongod", "--replSet", "rs0", "--bind_ip_all", "--keyFile", "/key/mongo-keyfile"]
ports:
- "27020:27017"
volumes:
- mongo4_data:/data/db
- ./key/mongo-keyfile:/key/mongo-keyfile:ro
networks:
- mongo-cluster
healthcheck:
test: ["CMD", "mongosh", "--eval", "db.adminCommand('ping')"]
interval: 5s
timeout: 5s
retries: 5
Sau đó chạy:
docker compose up -d mongo4
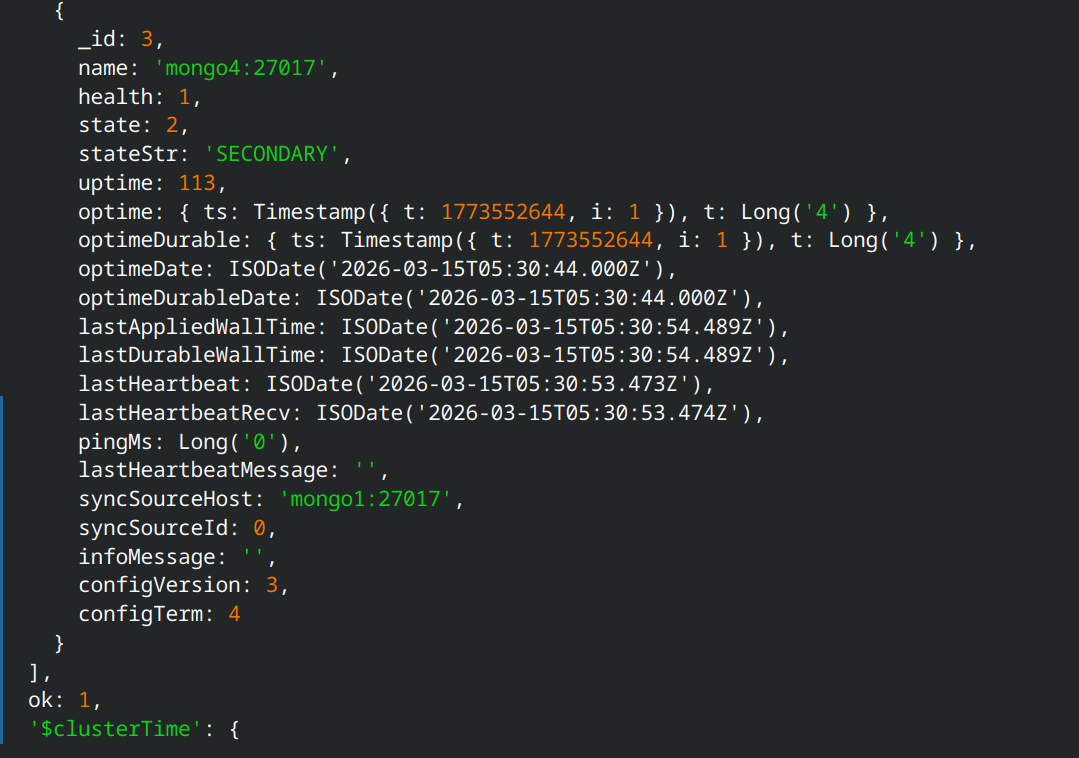
Vào mongosh của node mongo1 để chạy lệnh rs.add thêm node này vào:
rs0 [direct: primary] test> rs.add({ host: "mongo4:27017", priority: 1, votes: 1 })
{
ok: 1,
'$clusterTime': {
clusterTime: Timestamp({ t: 1773552541, i: 1 }),
signature: {
hash: Binary.createFromBase64('kwPA4k4lz/+LRy4cml0poA7tqsY=', 0),
keyId: Long('7617323150283374598')
}
},
operationTime: Timestamp({ t: 1773552541, i: 1 })
}
rs0 [direct: primary] test>
Cuối cùng kiểm tra trạng thái bằng rs.status()
Sharded clusters
Bài toán ta cần giải quyết như sau: Khi dữ liệu ngày càng lớn, thì việc lưu trữ cũng như truy vấn dữ liệu sẽ trở nên khó khăn hơn. Có hai giải pháp để giải quyết vấn đề này đó là vertical scaling và horizontal scaling. Vertical scaling là giải pháp tăng khả năng xử lí của một máy chủ đơn lẻ bằng cách nâng cấp CPU, RAM, đĩa lưu trữ, v.v… Tuy nhiên với giới hạn công nghệ hiện tại thì phương pháp này vẫn có những hạn chế nhất định. Horizontal scaling là giải pháp chia nhỏ dữ liệu và tải chúng lên nhiều máy chủ khác nhau. MongoDB hỗ trợ horizontal scaling thông qua sharding.
Một mongodb sharded cluster bao gồm 3 thành phần chính như sau:
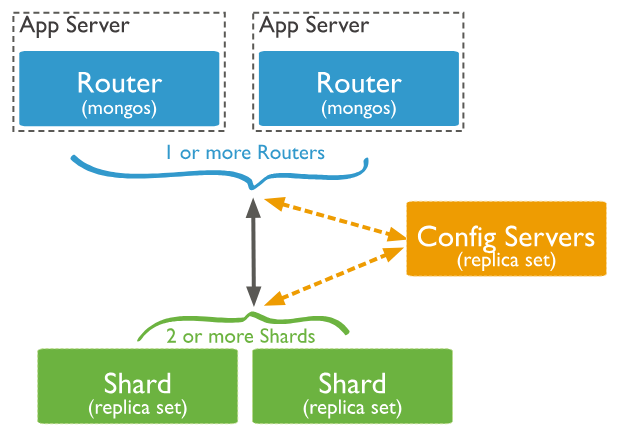
- Shard: mỗi shard chứa một phần dữ liệu đã được chia nhỏ. Hơn nữa, shard phải được deploy như một replica set.
- mongos: mongos hoạt động dưới dạng một query router, tương tác giữa ứng dụng và Sharded Cluster
- config server: config server là nơi lưu trữ metadata và cấu hình cho cluster. Config server cũng phải được deploy như một replica set để đảm bảo tính sẵn sàng cao.
MongoDB sử dụng shard key để xác định cách dữ liệu được phân phối trên các shard. Shard key chứa một hoặc nhiều trường có trong document, và nó sẽ được sử dụng để quyết định document đó sẽ được lưu vào shard nào.
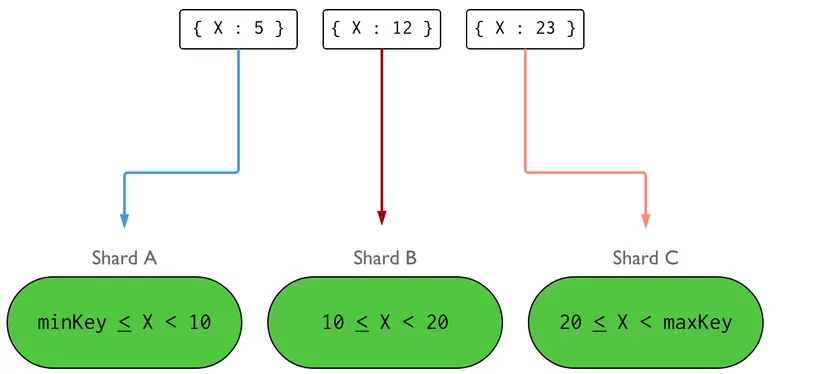
Demo:
Tạo file docker-compose.sharding.yml. Mình có tạo sẵn trên github mọi người có thể tham khảo thử hoặc tự viết lại từ đầu một file cho riêng mình: Link
Phần tiếp theo là config cho các replica set. Mọi người cần vào từng mongosh của các node để chạy các lệnh rs.initiate.
rs.initiate(
{
_id : "cfgReplSet",
configsvr: true,
members:
[
{ _id : 0, host: "cfg-a:27017" },
{ _id : 1, host: "cfg-b:27017" },
{ _id: 2, host: "cfg-c:27017" }
]
}
)
rs.initiate({
_id: "sh1ReplSet",
members: [
{ _id: 0, host: "sh1-a:27017" },
{ _id: 1, host: "sh1-b:27017" },
{ _id: 2, host: "sh1-c:27017" }
]
})
rs.initiate({
_id: "sh2ReplSet",
members: [
{ _id: 0, host: "sh2-a:27017" },
{ _id: 1, host: "sh2-b:27017" },
{ _id: 2, host: "sh2-c:27017" }
]
})
Các trường giá trị được dùng trong replica set configuration mọi người xem tại đây
Sau khi khởi tạo các replica set xong thì mình cần vào mongos để thêm các shard này vào:
sh.addShard("sh1ReplSet/sh1-a:27017,sh1-b:27017,sh1-c:27017")
sh.addShard("sh2ReplSet/sh2-a:27017,sh2-b:27017,sh2-c:27017")
Vậy là xong những phần cơ bản về MongoDB Cluster.
Triển khai trên Cloud như thế nào?
Toàn bộ phần demo bên trên được triển khai bằng docker compose nhằm hiểu sơ qua cách MongoDB cluster hoạt động như thế nào. Và như mọi người thấy thì tất cả các node đều chạy trên cùng một máy cho nên nó không mang lại nhiều ý nghĩa lắm.
Bài toán mà replica set giải quyết đó là đảm bảo tính sẵn sàng và dự phòng cao cho hệ thống còn sharding giải quyết bài toán horizontal scaling.
Cho nên ta chỉ thực sự hiểu rõ được ý nghĩa của hai cơ chế này khi triển khai trên các public cloud services. Ở đây mình sẽ chọn AWS để thực hành vì nó phổ biến nhất.
… UPDATING …
Vector Search and RAG
Một ứng dụng quan trọng của MongoDB đó là hỗ trợ cho các hệ thống RAG. Trong phần này mình sẽ giải thích RAG là gì và đề xuất hướng triển khai RAG với MongoDB
RAG là gì?
RAG hay Retrieval-Augmented Generation (RAG) là một khả năng giúp năng cao khả năng của mô hình sinh bằng cách kết hợp với tri thức bên ngoài. Phương pháp này thực hiện bằng cách truy xuất thông tin liên quan từ kho tài liệu (tri thức) và sử dụng chúng cho quá trình sinh câu trả lời dựa trên LLMs.
Để thực hiện ý tưởng trên thì ta cần trải qua 2 công đoạn chính:
-
Đầu tiên là indexing documents, ta cần đánh chỉ mục các tài liệu này một cách hợp lí làm sao cho con chatbot có thể tìm kiếm thông tin liên quan tới câu hỏi một cách nhanh chóng và chính xác.
-
Tiếp theo là retrieval, truy xuất dữ liệu từ các chỉ mục và dùng làm context cho LLM để giải quyết câu hỏi.
Chi tiết từng phần như sau.
- Đầu tiên là bước extract, ta cần trích xuất thông tin từ dữ liệu thô.
- Dữ liệu thô này sau đó sẽ được chia nhỏ thành các chunks.
- Chuyển đổi các chunks này thành các vector embeddings.
- Lưu trữ các vector này vào trong một vector database.
RAG Pipeline
Pipeline có thể hình dung đơn giản như sau:
-
Tạo vector database: convert dữ liệu tri thức của ta thành các vector và lưu trữ chúng vào một vector database
-
User input: user cung cấp câu truy vấn (query) cho chatbot
-
Information retrieval: dựa trên truy vấn của user, hệ thống sẽ tiến hành quét qua các vector trong database để xác định các phân đoạn tri thức nào có ngữ nghĩa tương đồng với câu truy vấn của người dùng
-
Combining data: kết hợp các phân đoạn tri thức đã được truy xuất với câu truy vấn của người dùng để tạo thành một prompt hoàn chỉnh
-
Generate text: Câu prompt này sau đó sẽ được gửi đến LLM để tạo ra câu trả lời dựa trên thông tin đã được truy xuất và câu hỏi của người dùng.
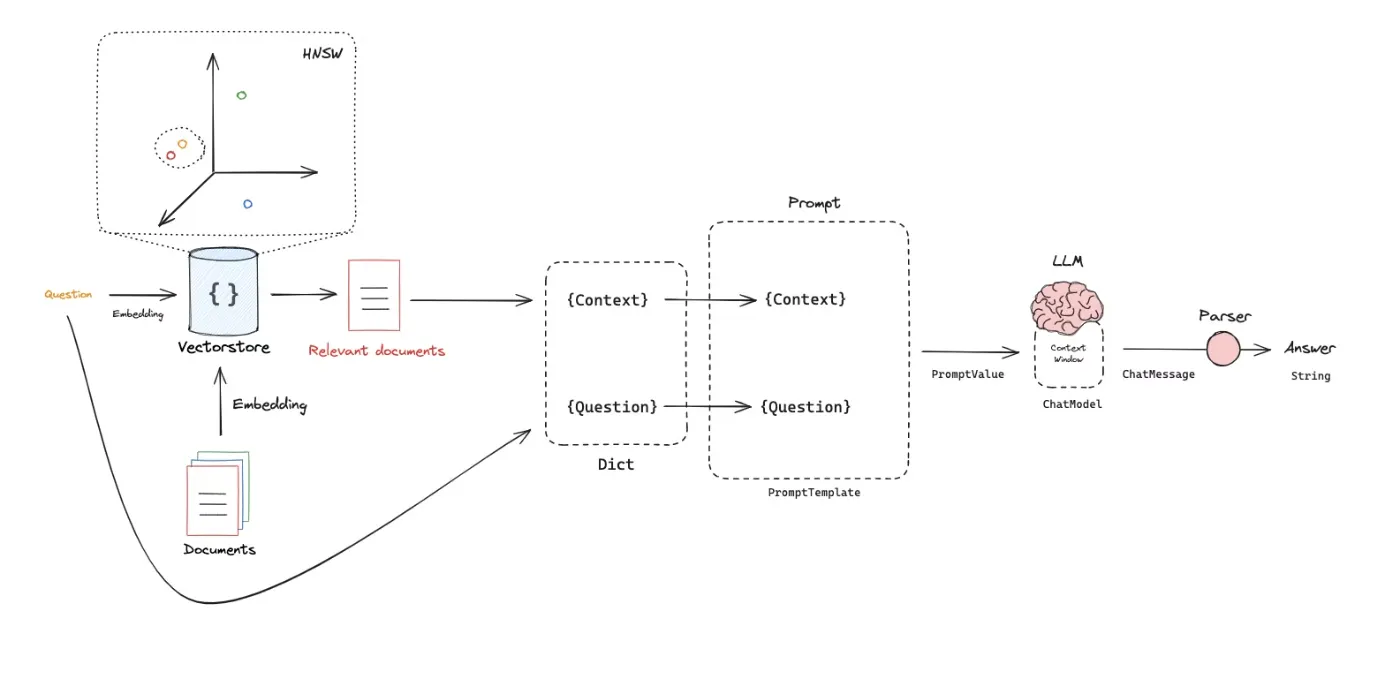
Thực hành
Mình sẽ thử triển khai một RAG Pipeline đơn giản.
Trước tiên cần cài đặt một môi trường ảo, ở đây mình sẽ dùng conda. Ngoài ra mọi người có thể thử sử dụng uv.
conda create -n ctf-agent python=3.12 -y
conda activate ctf-agent
pip install langchain langchain-google-genai langchain-community langchain-core
pip install langchain-text-splitters
Tiếp theo kiểm tra mô hình LLM nào mà api key có thể truy cập được. Ở đây mình xài gemini api key (vì openai éo cho xài free mà phải nạp)
from google import genai
from dotenv import load_dotenv
load_dotenv()
import os
# CHECK IF API KEY IS OKAY OR NOT
gemini_key = os.environ["GOOGLE_API_KEY"]
def check_gemini_model(api_key):
client = genai.Client(api_key=api_key)
usable = []
try:
models = client.models.list()
for model in models:
if "gemini" not in model.name.lower():
continue
try:
client.models.generate_content(
model = model.name,
contents = 'hi'
)
usable.append(model.name)
except Exception as e:
pass
except Exception as e:
pass
return usable
# gemini_use = check_gemini_model(gemini_key)
# print(gemini_use)
# ['models/gemini-2.5-flash', 'models/gemini-flash-latest', 'models/gemini-flash-lite-latest', 'models/gemini-2.5-flash-lite', 'models/gemini-3-flash-preview', 'models/gemini-3.1-flash-lite-preview', 'models/gemini-robotics-er-1.5-preview']
print("gemini ok")
Để xử lí dữ liệu tri thức, mình cần chuyển nó về dưới dạng văn bản thuần túy.
Có 2 lựa chọn cho kiểu văn bản đó là Markdown hoặc txt. Ở đây mình sẽ lựa chọn Markdown vì nó có cấu trúc tiêu đề rõ ràng hơn so với txt là một khối dữ liệu liền mạch.
Ví dụ một cấu trúc cho file markdown như sau:
# [Tên Challenge]
**Category:** [Web / Pwn / Rev / Crypto / Forensics / Misc]
## Description
> [Mô tả của challenge do ban tổ chức cung cấp]
## Overview
[Tóm tắt ngắn gọn nhất về mục tiêu của bài và công nghệ/ngôn ngữ được sử dụng]
## Technical details
[Đi thẳng vào vấn đề kỹ thuật cốt lõi. BỎ QUA các bước recon cơ bản (như file, checksec, nmap, v.v.) trừ khi nó là trọng tâm của bài. Xác định ngay lỗ hổng/thuật toán chính là gì và giải thích ngắn gọn cơ chế lỗi. Ví dụ: "Chương trình bị lỗi Buffer Overflow tại hàm X do hàm Y không kiểm tra độ dài", hoặc "Hệ mã RSA sử dụng e quá nhỏ dẫn đến Broadcast Attack".]
## Proof-of-Concept
[Tuyệt đối không dump toàn bộ script exploit thành một khối duy nhất mà không giải thích. Bạn phải miêu tả từng bước khai thác và trích xuất đoạn code xử lý việc đó ra ngay bên dưới lời giải thích.
Ví dụ:
- Bước 1: Leak địa chỉ libc thông qua lỗi Format String.
`[Đoạn code snippet thực hiện việc leak]`
- Bước 2: Tính toán base address và gọi system('/bin/sh').
`[Đoạn code snippet tương ứng]`]
## P/S
[Phần này KHÔNG bắt buộc. Chỉ thêm vào nếu có các Takeaways quan trọng, bài học rút ra, hoặc các notes về những cách giải thay thế (unintended solution).]
Dùng phương thức TextLoader và DirectoryLoader để load dữ liệu từ các file markdown này:
from langchain_community.document_loaders import TextLoader, DirectoryLoader
loader = DirectoryLoader(
"./Documents",
glob = "**/*.md",
loader_cls = TextLoader,
show_progress=True,
use_multithreading=True,
silent_errors=True
)
documents = loader.load()
print(f"Loaded {len(documents)} documents")
print(documents[0].metadata)
print(documents[0].page_content[:500])
Tiếp theo ta cần chia nhỏ các tài liệu này thành các chunks. Đối với file md ta sẽ sử dụng hai phương thức là MarkdownHeaderTextSplitter và RecursiveCharacterTextSplitter.
Do markdown chia section theo các header nên cần phải chunk bằng MarkdownHeaderTextSplitter trước để giữ nguyên cấu trúc của tài liệu. Sau đó mới tiếp tục chia nhỏ hơn bằng RecursiveCharacterTextSplitter để đảm bảo độ dài của mỗi chunk không vượt quá giới hạn cho phép của mô hình LLM.
from langchain_text_splitters import MarkdownHeaderTextSplitter, RecursiveCharacterTextSplitter
header_split = [
('#', 'h1'),
('##', 'h2')
]
md_splitter = MarkdownHeaderTextSplitter(
headers_to_split_on=header_split
)
sections = []
for doc in documents:
splits = md_splitter.split_text(doc.page_content)
for s in splits:
s.metadata.update(doc.metadata)
sections.append(s)
chunk_splitter = RecursiveCharacterTextSplitter(
chunk_size=800,
chunk_overlap=150,
separators = ["\n\n", "\n", ". ", " ", ""])
final_chunk = chunk_splitter.split_documents(sections)
print(final_chunk[0].metadata)
Sau khi chunk ta sẽ embed các chunks này thành các embedding vector và lưu chúng trong một vector database. Gemini có cung cấp một embedding model free là gemini-embedding-001.
Check model cho embedding vector:
import os
from dotenv import load_dotenv
from google import genai
load_dotenv()
client = genai.Client(api_key=os.environ["GOOGLE_API_KEY"])
model_name = "gemini-embedding-001"
try:
result = client.models.embed_content(
model=model_name,
contents="RSA small exponent attack"
)
emb = result.embeddings[0].values
print("OK:", model_name)
print("Embedding length:", len(emb))
except Exception as e:
print("FAILED:", model_name)
print(type(e).__name__, e)
Google api key thì cho xài free gemini-embedding-001 với embedding length là 3072.
Thực hiện các bước embed -> store -> search. Để phục vụ việc demo đơn giản thì mình sẽ sử dụng Chroma làm vector database. Trong Langchain có hỗ trợ mongodb thông qua phương thức MongoDBAtlasVectorSearch mà ta sẽ tìm hiểu ở phần sau của bài viết.
embeddings = GoogleGenerativeAIEmbeddings(
model="models/gemini-embedding-001"
)
vector_store = Chroma.from_documents(
documents = final_chunk,
embedding = embeddings,
persist_directory="./chroma_db",
)
print("Done embedding and storing documents in Chroma.")
result = vector_store.similarity_search(
"How do we recover phi(n) from d",
k=3
)
for i, doc in enumerate(result):
print("=" * 80)
print(f"Result {i+1}")
print(doc.metadata)
print(doc.page_content[:500])